Huffman-codes: voorbeelden, toepassingen
Op dit moment denken maar weinig mensen over het feit,hoe compressie werkt. In vergelijking met het verleden is het gebruik van een personal computer veel eenvoudiger geworden. En vrijwel elke persoon die met het bestandssysteem werkt gebruikt archieven. Maar weinig mensen denken na over hoe ze werken en over welk principe de compressie van bestanden is. De allereerste versie van dit proces was de Huffman-codes, en ze worden nog steeds gebruikt in verschillende populaire archivers. Veel gebruikers denken zelfs niet hoe gemakkelijk het is om het bestand te comprimeren en volgens welk schema het werkt. In dit artikel zullen we kijken hoe compressie wordt uitgevoerd, welke nuances helpen om het coderingsproces te versnellen en te vereenvoudigen, en we zullen uitzoeken wat het principe is om een codeerboom te bouwen.
Geschiedenis van het algoritme
Het allereerste algoritme voor een effectiefcodering van elektronische informatie was de code die Huffman in het midden van de twintigste eeuw had voorgesteld, namelijk in 1952. Het is momenteel het belangrijkste basiselement van de meeste programma's die zijn gemaakt om informatie te comprimeren. Op dit moment zijn een van de meest populaire bronnen die deze code gebruiken, ZIP-, ARJ-, RAR-archieven en vele anderen.

Het principe van efficiënte codering
De basis voor het Huffman-algoritme is een schema,Hiermee kunnen de meest waarschijnlijke, meest voorkomende symbolen worden vervangen door codes van een binair systeem. En degenen die minder vaak voorkomen, worden vervangen door langere codes. De overgang naar lange Huffman-codes vindt alleen plaats nadat het systeem alle minimumwaarden heeft gebruikt. Met deze techniek kunt u de lengte van de code voor elk teken van het oorspronkelijke bericht als geheel minimaliseren.

Huffman's code, voorbeeld
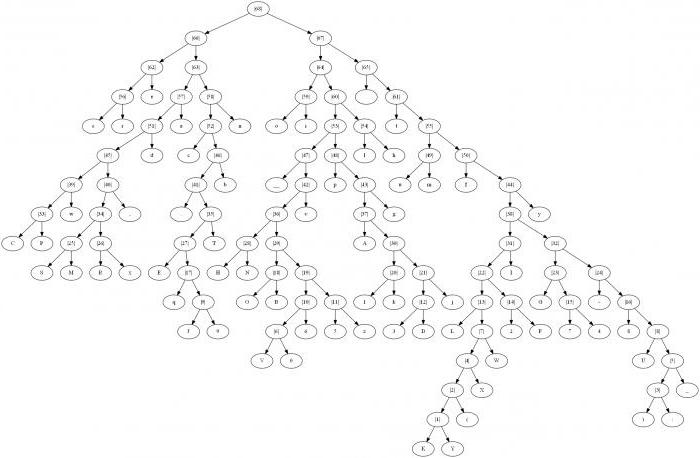
Laten we het algoritme illustrereneen grafische versie van de constructie van een codestructuur. Om deze methode effectief te gebruiken, is het de moeite waard om de definitie van enkele waarden die nodig zijn voor het concept van deze methode te verduidelijken. De reeks bogen en knopen die van knoop naar knoop worden geleid, wordt meestal een grafiek genoemd. De boom zelf is een grafiek met een reeks bepaalde eigenschappen:
- in elk knooppunt kan niet meer dan één van de bogen worden ingevoerd;
- een van de knooppunten moet de wortel van de boom zijn, dat wil zeggen dat er helemaal geen boog in moet komen;
- als je vanuit de root begint met het verplaatsen van bogen, moet dit proces het mogelijk maken om volledig in een van de knooppunten te komen.

Algoritme voor het construeren van een boom volgens Huffman
De constructie van de Huffman-code is gemaakt van lettersvan het invoeralfabet. Er wordt een lijst gemaakt met de knooppunten die vrij zijn in de toekomstige codestructuur. Het gewicht van elk knooppunt in deze lijst moet hetzelfde zijn als de kans dat de letter van het bericht correspondeert met dit knooppunt. In dit geval, een van de weinige gratis knooppunten van de toekomstige boom, wordt degene die het minst weegt gekozen. Als tegelijkertijd de minimumindicatoren in verschillende knooppunten worden waargenomen, is het mogelijk om willekeurig een van de paren te kiezen.

Verbetering van de compressie-efficiëntie
Om de compressie-efficiëntie te verhogen, is het noodzakelijk omde tijd voor het bouwen van een codestructuur om alle gegevens te gebruiken met betrekking tot de waarschijnlijkheid dat letters in een bepaald bestand aan een boom worden toegevoegd en niet om ze over een groot aantal tekstdocumenten te verspreiden. Als u eerst door dit bestand loopt, kunt u onmiddellijk de statistieken berekenen van hoe vaak letters van een te comprimeren object worden aangetroffen.
Versnelling van het compressieproces
Om het algoritme te versnellen, de definitie van lettersHet is niet nodig om indicatoren voor de waarschijnlijkheid van het voorkomen van deze of gene brief en de frequentie van het optreden ervan uit te voeren. Dankzij dit wordt het algoritme eenvoudiger en wordt er veel sneller mee gewerkt. Dit vermijdt ook de bewerkingen die verband houden met zwevende komma's en deling.
conclusie
Huffmans codes - eenvoudig en lang gevestigdalgoritme, dat nog steeds wordt gebruikt door veel bekende programma's en bedrijven. De eenvoud en duidelijkheid maken het mogelijk om effectieve compressieresultaten te bereiken voor bestanden van elke grootte en om de ruimte die ze innemen op de opslagschijf aanzienlijk te verminderen. Met andere woorden, het Huffman-algoritme is een lang bestudeerd en goed opgezet schema waarvan de relevantie tot op heden niet afneemt.